Research conducted during my time as a Research Associate for the CRITiCaL and EMPHASIS projects at Newcastle University, UK.
A King’s Ransom for Encryption: Ransomware Classification using Augmented One-Shot Learning and Bayesian Approximation
Newly emerging variants of ransomware pose an ever-growing threat to computer systems governing every aspect of modern life through the handling and analysis of big data. While various recent security-based approaches have focused on ransomware detection at the network or system level, easy-to-use post-infection ransomware classification for the lay user has not been attempted before. This research project investigates the possibility of classifying the ransomware a system is infected with simply based on a screenshot of the splash screen or the ransom note captured using a consumer camera commonly found in any modern mobile device. To train and evaluate this system, a sample dataset of the splash screens of 50 well-known ransomware variants is created. In this dataset, only a single training image is available per ransomware. Instead of creating a large training dataset of ransomware screenshots, we simulate screenshot capture conditions via carefully-designed data augmentation techniques, enabling simple and efficient one-shot learning. Moreover, using model uncertainty obtained via Bayesian approximation, we ensure special input cases such as unrelated non-ransomware images and previously-unseen ransomware variants are correctly identified for special handling and not mis-classified. Extensive experimental evaluation demonstrates the efficacy of this work, with accuracy levels of up to 93.6% for ransomware classification.
Training Dataset
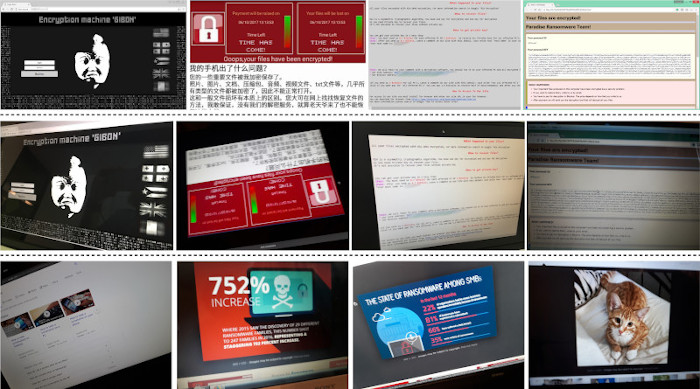
The models are trained on a dataset of splash screens and ransom notes of 50 different variants of ransomware. The entirety of the dataset can be directly downloaded from here or via a bash script on the project GitHub page. Within the dataset, a single image of a splash screen variant is available for all the ransomware classes. However, certain ransomware classes are associated with more than one splash screen. To test the performance of the approach, a balanced test set of 500 images (10 images per class) is created by casually taking screenshots of the ransomware images using two different types of camera phones (Apple and Android) from 6 different computer screens (with varying specifications, such as size, resolution, aspect ratio, panel type, screen coating, colour depth, etc.). This will be called the positive test dataset since all the images within this dataset need to be positively identified as ransomware and any model trained using our dataset should be certain about the predictions it makes with respect to the ransomware variants it has already observed. An additional set of 50 unrelated and/or non-ransomware images are captured from the same computer screens to evaluate the uncertainty estimates acquired using our Bayesian networks. This is the negative test dataset, as any model trained on our dataset should be very uncertain about this data since these screenshot images are not of and therefore should not be classified as any ransomware known to the model.
Proposed Approach
During training, the network can only see the sole image available for each splash screen variant. This lack of training data can significantly hinder generalisation as the model would simply overfit to the training distribution or simply memorise the few training images it sees. To prevent this, a carefully designed and tuned set of augmentation techniques is applied to the training images on the fly to simulate the test conditions (images being casually captured from a computer screen). The hyper-parameters associated with these augmentation techniques (probability, intensity, level, etc.) are determined using exhaustive grid-searches which are excluded here. The randomised augmentation approaches include:
- Rotation: randomly rotating the image with the angle of rotation in the range [-90°,90°].
- Contrast: randomly changing the image contrast by up to a factor of 2.
- Brightness: randomly changing the brightness by up to a factor of 3.
- Random occlusion: to primarily simulate distractors such as screen glare and reflection mostly in glossy screens (up to a quarter of the image size occluded with random elliptical shapes of randomly selected bright colours).
- Gaussian blur: with a radius of up to 5.
- Motion blur: simulating blurring effects caused by the movement of the camera during image capture (up to a movement length of 9 pixels).
- Defocus blur: simulating the camera being out of focus which is a common occurrence when a computer screen is being photographed (up to a kernel size of 9).
- Random colour perturbations: randomising hue by a maximum of 5% and saturating colours by a factor of up to 2.
- Random perspective: by up to 50% over each axis to simulate the varying camera angles when a screen is being photographed.
Experimental Results
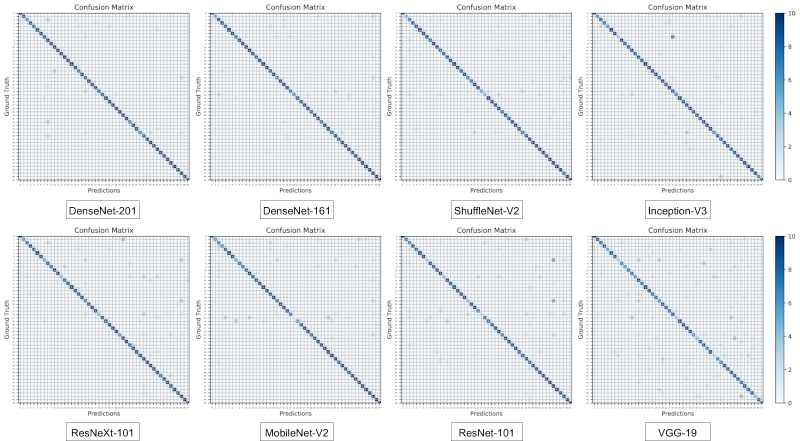
To achieve the highest possible levels of accuracy, we take advantage of various state-of-the-art image classification networks. With relatively high-resolution images (256*256) used as inputs, accuracy levels of up to 93.6% can be achieved using our full augmentation protocol and a DenseNet-201 network pre-trained on ImageNet. Additionally, by calculating model uncertainty when the model is evaluated using the positive and negative test data, we can assess the effectiveness of the uncertainty values. One would expect the model to be very uncertain when negative test images (unrelated images) are passed as inputs and on the other hand, the uncertainty values should be smaller when positive test data (ransomware screenshots) are seen by the network. Our experiments point to the same conclusions with uncertainty values being significantly higher in the presence of negative data.

Discussions and Future Work
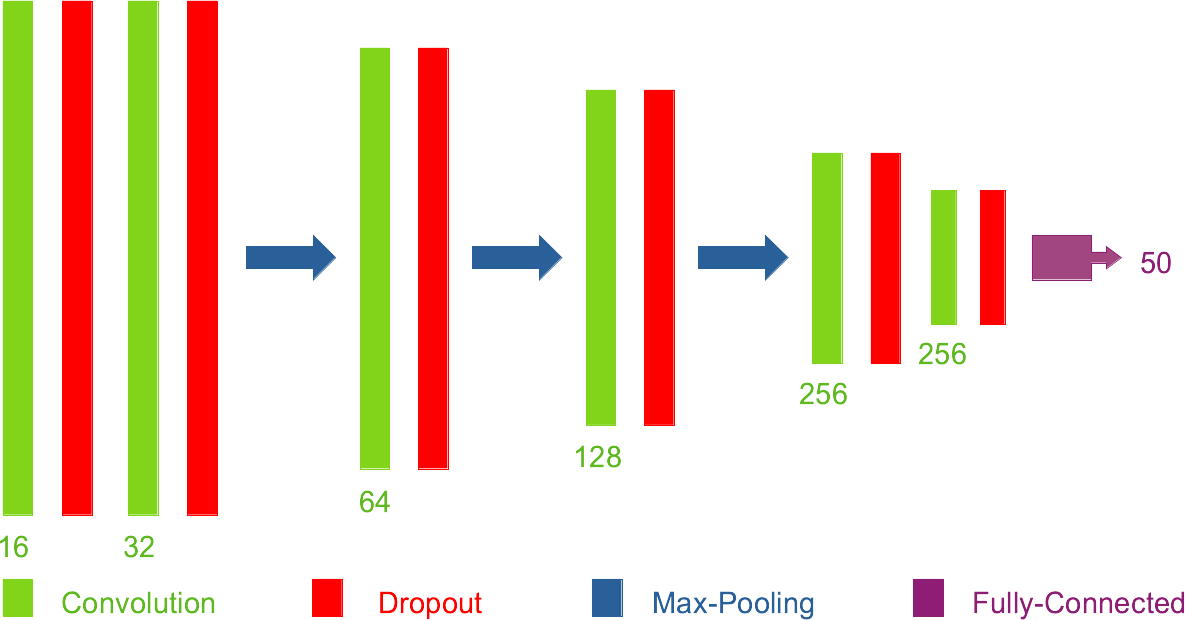
The approach is able to achieve high accuracy results using our augmentation techniques and deep convolutional neural networks such as DenseNet. However, since another important component of this work, model uncertainty, relies on introducing a dropout layer after every weight matrix within the model, convergence for very deep models such as DenseNet would be almost impossible, which is why we opted for using our own simplified network architecture. While this can sufficiently meet the requirements of the application through a possible two stage solution (the light-weight network measures the uncertainty of the model with respect to the input and if the value is low and special handling is not required, the deep network can be subsequently used to conduct the actual classification), future work can involve the use of Bayesian modules within each layer or a Bayesian last layer in the network, thus enabling the optimisation of much deeper networks with plausible uncertainty calculation capabilities. Additionally, if the parameters of the augmentation techniques could be learned during training instead of being laboriously tuned through extensive grid searches, the resulting efficient and stable training can lead to superior model performance.
Technical Implementation
All implementation is carried out using Python, PyTorch and OpenCV. All training and experiments were performed using a GeForce RTX 2080 Ti. The source code is publicly available.
Publication

Paper:
DOI: 10.1109/BigData47090.2019.9005540
arXiv: 1908.06750
Amir Atapour-Abarghouei, Stephen Bonner and Andrew Stephen McGough. "A King's Ransom for Encryption: Ransomware Classification using Augmented One-Shot Learning and Bayesian Approximation", in IEEE International Conference on Big Data, 2019. BibTeX
Code: PyTorch