Research conducted during my time as a Ph.D. student at Durham University, UK.

DepthComp: Real-time Depth Image Completion Based on Prior Semantic Scene Segmentation
This work addresses plausible hole filling in depth images in a computationally lightweight methodology that leverages recent advances in semantic scene segmentation. Firstly, we perform such segmentation over a co-registered color image, commonly available from stereo depth sources, and non-parametrically fill missing depth values based on a multi-pass basis within each semantically labelled scene object. Within this formulation, we identify a bounded set of explicit completion cases in a grammar inspired context that can be performed effectively and efficiently to provide highly plausible localised depth continuity via a case-specific non-parametric completion approach. Results demonstrate that this approach has complexity and efficiency comparable to conventional interpolation techniques but with accuracy analogous to contemporary depth filling approaches. Furthermore, we show it to be capable of fine depth relief completion beyond that of both contemporary approaches in the field and computationally comparable interpolation strategies.
Proposed Approach
The approach uniquely leverages recent advances in semantic scene segmentation, such that completion can now be performed with reference to object boundaries within the scene. Here, focusing on the challenge of outdoor driving scenes, we utilise SegNet, a deep convolutional architecture trained for urban scene segmentation in the context of vehicle autonomy. However, in general, any such approach that can perform accurate and efficient object or instance wise scene segmentation can suffice. Alternative segmentation models (object, instance or otherwise) can lead to similar results, provided they produce limited mis-segmentation artefacts.

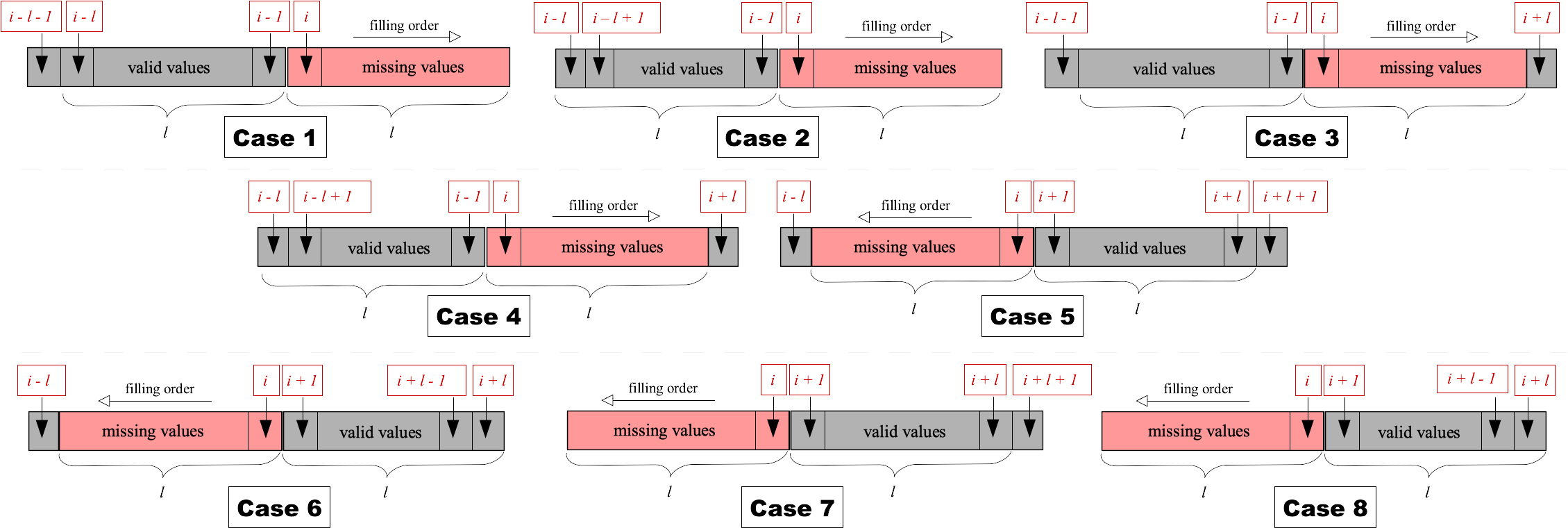
- Case 1: where the constrained hole ends at the rightmost boundary of the object, i.e. all depth values on the right side of the current object are missing, but the number of preceding depth values to the left of the hole exceeds the length of the hole itself. Since such holes extend to the rightmost pixel in the current object, no depth information is available to the right of the hole, and as such there is no need to account for any in-filling continuity. Consequently, it suffices to identify the pattern of depth change to the left of the hole, the length of which is greater than the length of the hole itself, and propagate this pattern rightward, replicating the texture and relief detail present within the object boundary.
- Case 2: where the constrained hole ends at the rightmost boundary the object (as per Case 1) but here, the number of preceding depth values to the left of the hole is exactly the same as the length of the hole itself. Here we proceed as per Case 1, but with less depth information present to the left of the hole to identify and propagate any pattern rightward.
- Case 3: where the constrained hole does not reach the leftmost or rightmost boundary edges of the scene object, i.e. the hole is contained within the object itself with valid depth values to both the left and right. In this case, the pattern of depth change can be sampled from either side depending on valid depth value availability within the same scene object. To predict the missing depth values correctly considering the pattern of texture and relief, continuity between the valid values to the left and the right side of the hole is taken into account. The continuity coefficient (slope) is utilised to ensure that the predicted values plausibly bridge the depth values to the left and right of the hole. The pattern of change in the valid values is propagated rightward with each value being multiplied by slope, calculated by dividing the difference between the values surrounding the hole into the difference between the values surrounding the sample area.
- Case 4: as per Case 3, but such that the number of valid depth values to the left of the constrained hole is exactly the same as the length of the hole itself. The difference between this completion process and that of Case 3 is the same as the difference between Cases 1 and 2. The completion order and the slope coefficient are applied similarly to Case 3.
- Case 5: where the constrained hole does not reach the leftmost or rightmost boundary of the object (as per Case 3) but the number of valid depth values to the left of the hole is smaller than the length of the hole itself, while sufficient valid depth values exist to the right of the hole for completion. Following a symmetric completion process to that of Case 3, the pattern of change in the valid depth values is propagated leftward.
- Case 6: as per Case 5, but such that the number of valid depth values to the right of the constrained hole is exactly the same as the length of the hole itself. Following a symmetric completion process to that of Case 4, the pattern of change in the valid depth values is propagated leftward.
- Case 7: where the constrained hole starts at the leftmost boundary edge of the scene object (symmetric to that of Case 1). Conversely, the number of valid values on the right of the hole is greater than the length of the hole itself. Following a symmetric completion process to that of Case 1, the pattern of change in the valid depth values is propagated leftward.
- Case 8: as per Case 7, but such that the number of valid depth values to the right of the constrained hole is exactly the same as the length of the hole itself. The difference between this completion process and that of Case 7 is the same as the difference between Cases 1 and 2. The depth completion order and the slope coefficient are applied similarly to Case 7. Since no continuity is required, slope=1.
- Case 9: where the constrained hole extends to the rightmost pixel within the object (similar to Cases 1 and 2), but we cannot employ a non-parametric approach (as per Cases 1 and 2) because the number of valid depth values to the left of the hole is smaller than the length of the hole itself. As a result, there is not enough information to accurately fill these holes. Instances of these cases are left unfilled if identified during the scan in progress. In subsequent scans, many of these unresolvable (Case 9) patterns are broken due to the use of alternating row-wise and column-wise scan passes (resulting in an alternative resolvable case instance). For Case 9 instances that are not resolved after all three image passes, simple (cubic) interpolation is used (in an insignificant number of cases).
- Case 10: where the constrained hole extends to the leftmost pixel within the scene object (similar to Cases 7 and 8), but again we cannot employ a non-parametric approach (as per Cases 7 and 8) because the number of valid depth values to the right of the hole is smaller than the length of the hole itself. As a result, there is again not enough information to accurately fill these holes, and we proceed as per Case 9.
- Case 11: where the constrained hole is located in the middle of an object but with insufficient valid depth values to the left and right side to facilitate non-parametric filling. Again, there is not enough information to accurately fill these holes, and we proceed as per Case 9.
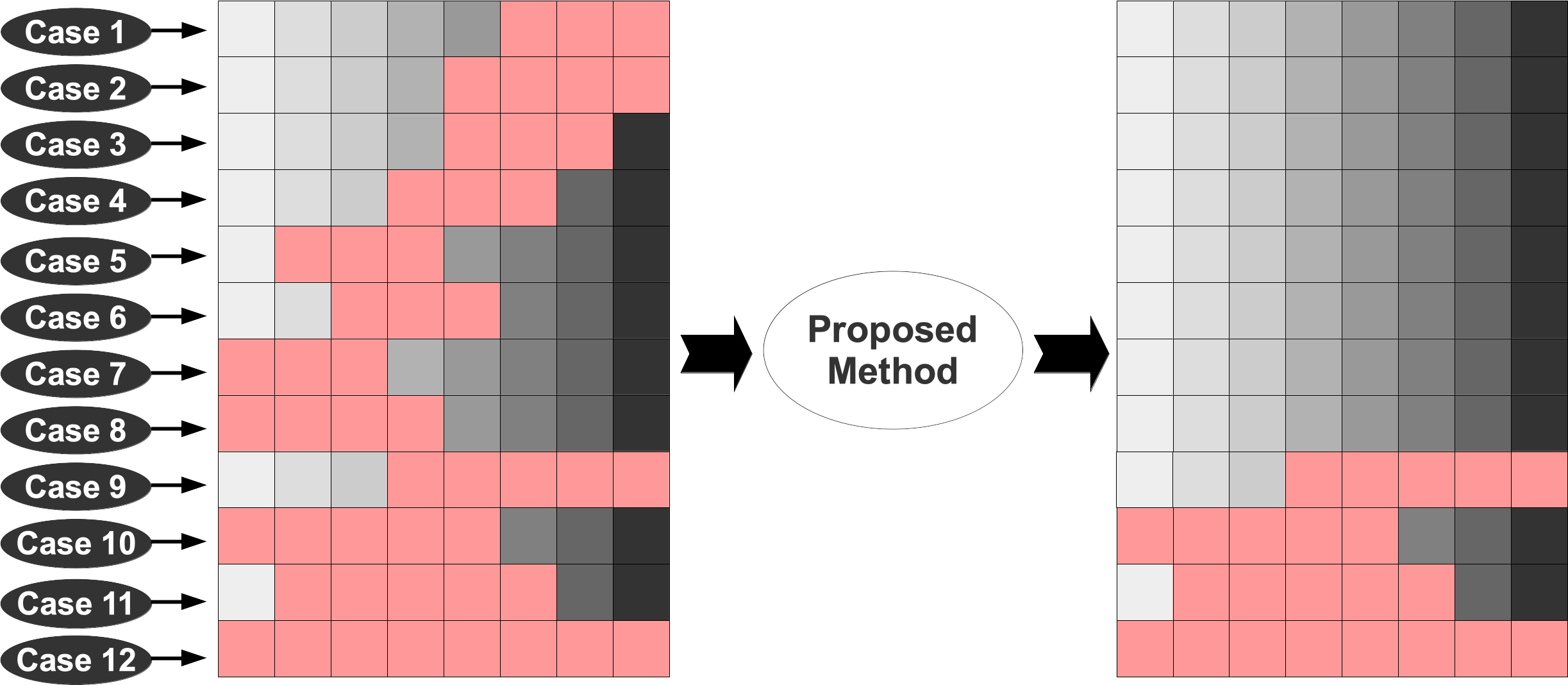
- Case 12: where the constrained hole spans over the entire length of the scene object, (i.e. no depth is available for an object known to be present in the scene from the semantically segmented color image) making it the most challenging case of all. For instances of this case not resolved within the three scan passes (row-wise, column-wise, secondary row-wise), a clear ambiguity exists as there is no valid depth information available for the object at all. Experiments on the KITTI demonstrate that less than 2% of hole occurrences cannot be completed using our three-pass approach (row-wise, column-wise, secondary row-wise) through the resolution outlined. This includes the challenging Case 12, which cannot be accurately filled due to the lack of surrounding valid depth values. Although our three pass processing of these 12 cases noticeably uses no explicit inter-row/column support regions (from adjacent row/columns) as may be ordinarily expected, this is in fact implicit in our formulation based on the use of the prior region-based scene segmentation, which inherently provides semantically defined support regions.
Experimental Results
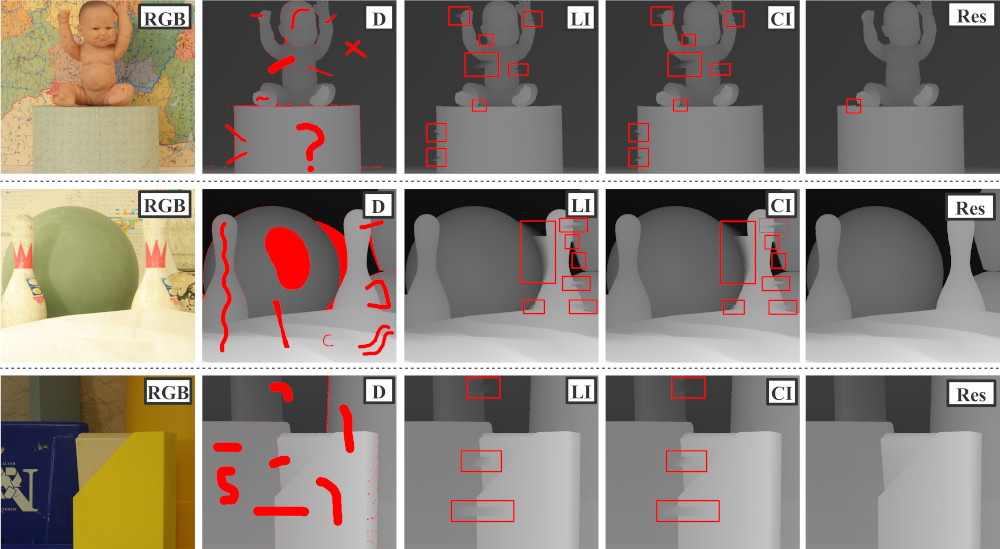
With the asymptotic runtime of O(n) for n image pixels, the proposed method is comparable to simple interpolation methods in complexity but with accuracy exceeding that of significantly more complex methods. The proposed approach is evaluated using the KITTI and Middlebury datasets along with synthetic depth images created to assess the ability of the approach to deal with fine surface relief. Despite extremely low computational complexity, the approach produces very clear and accurate results. For further numerical and qualitative results, please refer to the paper.
Technical Implementation
All implementation is carried out using C++ and OpenCV. No GPUs were used and all experiments were performed on a 2.30GHz CPU using 8GB of memory. The source code is publicly available.
Supplementary Video
For further details of the proposed approach and the results, please watch the video created as part of the supplementary material for the paper.
Publication

Paper:
DOI: 10.5244/C.31.58
Citation:
Amir Atapour-Abarghouei and Toby P. Breckon. "DepthComp: Real-time Depth Image Completion Based on Prior Semantic Scene Segmentation", in British Machine Vision Conference (BMVC), 2017.
BibTeX
Code: C++